打造动漫下载器(二):python使用playwright进行网页分析,实现动漫的下载
python使用playwright进行网页分析,实现动漫的下载
接前篇文章,已经成功的获取到了播放器的链接,接下来只需要获得其中视频真正的链接就可以访问来下载视频
playwright进行网页分析
由于播放器的链接是动态加载,简单的requests已经无法获取到完整的源码,因此可以使用selenium或者playwright,而playwright操作更为简单,安装也方便,只需要在命令行中运行pip install playwright即可安装,随后playwright install就可以直接下载浏览器驱动
具体用法如下
1 | from playwright.sync_api import sync_playwright |
没错就是如此简单,每一行命令和实际在浏览器中操作基本一致,而只需要等待页面加载完成,就可以获取到完整的源码,那么我们可以接着上一篇内容,将最后获得的链接放入page.goto()中,就可以对动态加载的页面进行分析
这里对一个动漫的播放器进行分析,获取其中的视频真正的链接,如图所示
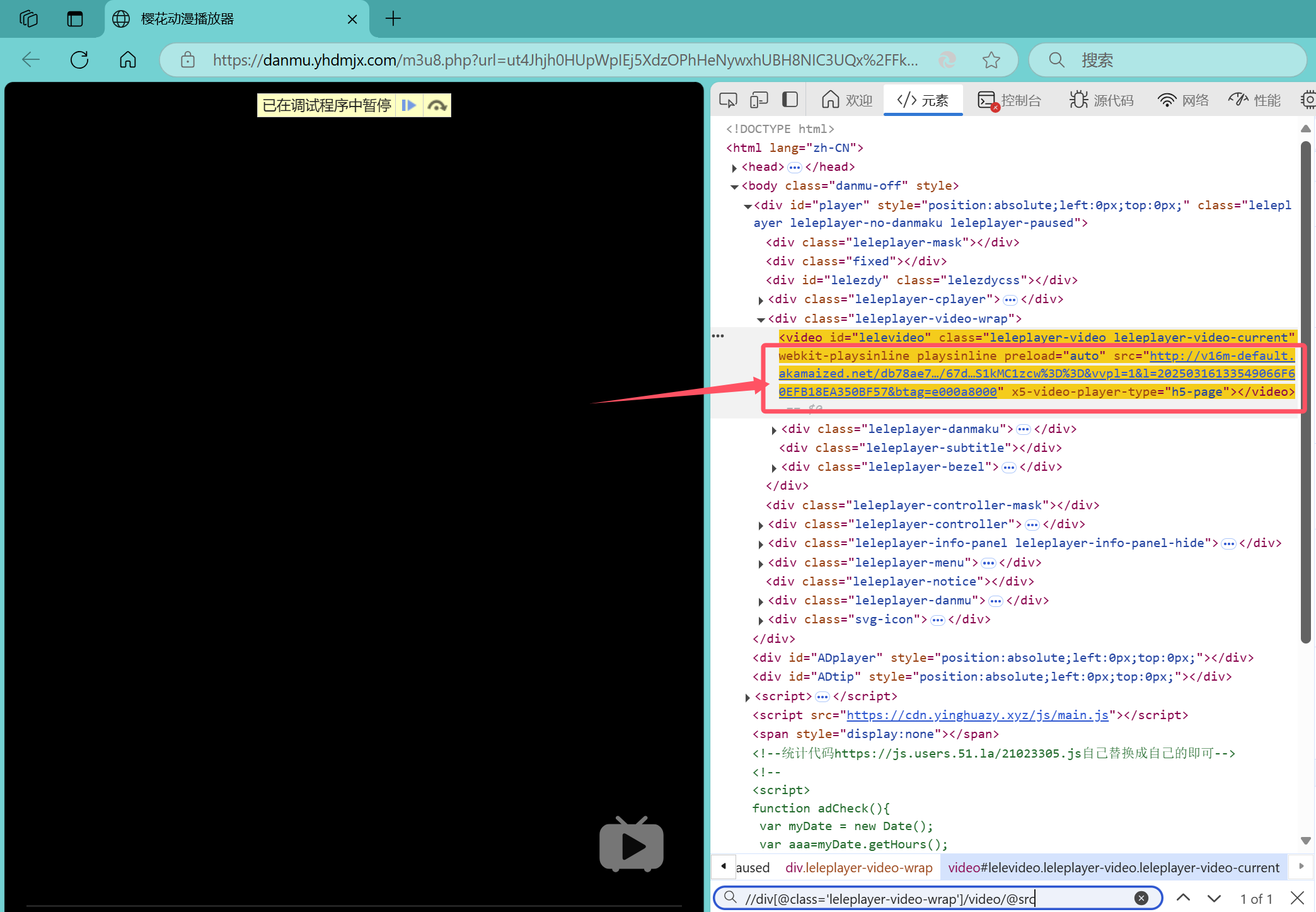
视频链接存放在video的src属性中,对应xpath为//div[@class='leleplayer-video-wrap']/video/@src,在一个新的python程序中进行测试,效果如下
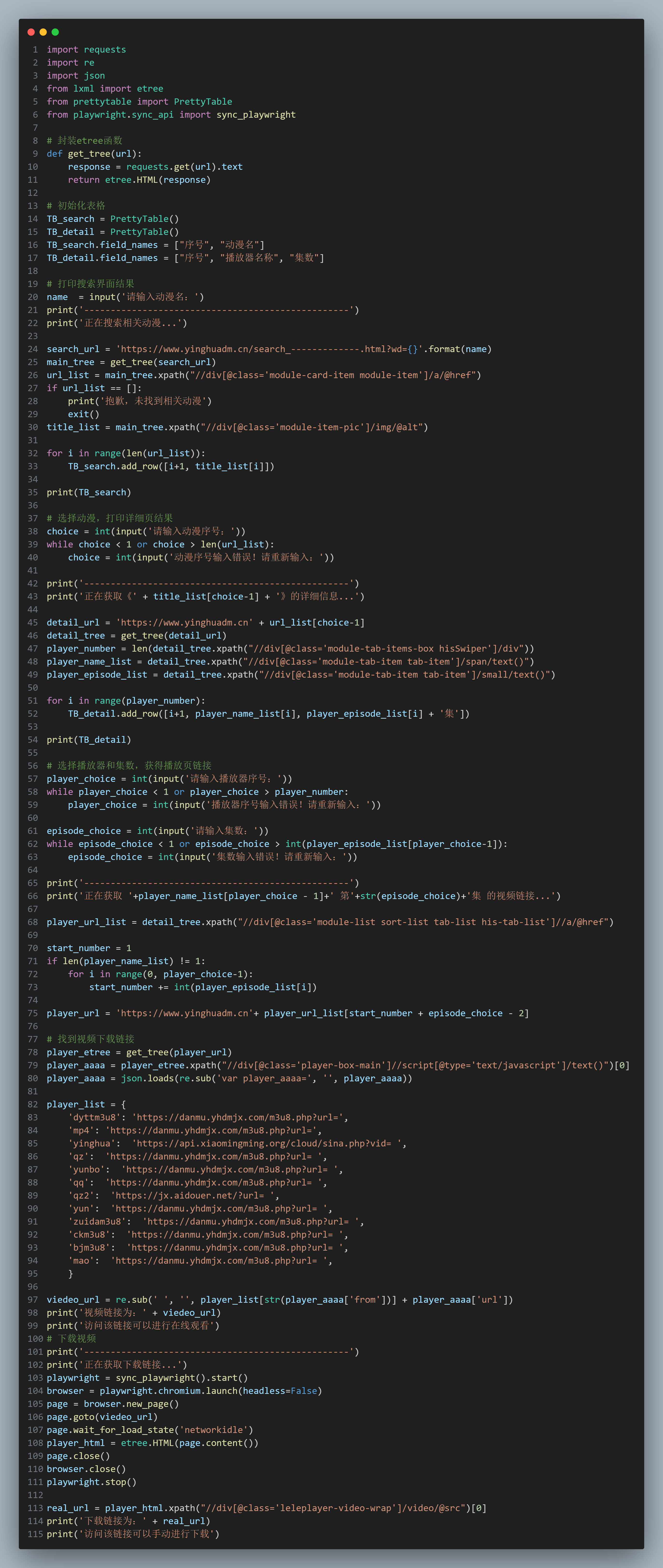
最终目的达到,可以通过这个来访问动漫的下载地址,完整代码如下
效果展示
可以观看视频,完整的效果如下
附加
可以在获取下载链接之后,使用requests访问,读取数据并保存到本地,创建mp4文件来实现最终的下载,这里不再赘述,有兴趣的可以自行尝试
